
 No hay una disciplina científica con más «eurekas» que el saber de componentes. Como no entendemos bien los intríngulis de la materia, el descubrimiento de componentes que tienen un montón particular de propiedades siempre ha sido un proceso tremendamente fortuito que requiere cantidades ingentes de buena ciencia, suerte y paciencia.
No hay una disciplina científica con más «eurekas» que el saber de componentes. Como no entendemos bien los intríngulis de la materia, el descubrimiento de componentes que tienen un montón particular de propiedades siempre ha sido un proceso tremendamente fortuito que requiere cantidades ingentes de buena ciencia, suerte y paciencia.
La cronica de la tecnología está llena de ideas revolucionarias que se quedan durante décadas metidas en un cajón esperando a que seamos capaces de localizar el material concreto que permita hacerlas realidad. Por eso, desde hace años, los investigadores tratan utilizar la inteligencia artificial para tratar de agilizar estos procesos.
Actualmente, un equipo de expertos del Lawrence Berkeley National Laboratory han comprobado que debido a una combinación de aprendizaje automático no supervisado y ‘minería de textos’ se pueden procesar millones de artículos investigadores y localizar relaciones que, incluso hoy, permanecían «ocultas». Hoy es en el saber de los componentes, pero no se va a quedar ahí.
IAs para revelar componentes
 Nature
NatureSolo necesitamos soñar las innumerables combinaciones de componentes y estructuras posibles, para darnos cuenta de que el desarrollo de componentes es una tarea que no se acaba jamás. Sobre todo porque los procedimientos tradicionales para el examen de la composición de los componentes consumen demasiado tiempo, son tremendamente aburridos y exageradamente caros. Según varios expertos, se requiere un promedio de 10 años para que un laboratorio desarrolle un nuevo material y 20 años para que ese material pueda producirse en masa.

Machine Learning y Deep Learning: cómo entender las claves del presente y futuro de la inteligencia artificial
De ahí que el aprendizaje automático se haya convertido en una gran esperanza dentro del campo. Incluso actualmente, la mayoría de enfoques se han basado en equipos que nos permitieran asignar determinados parámetros estructurales (como las propiedades de la composición del material) y determinadas propiedades físicas o electrónicas. El plan es utilizar esos equipos para predecir las propiedades finales a partir de las iniciales, algo que no podemos hacer incluso y que nos ahorraría demasiado trabajo. Vamos haciendo avances, pero son enfoques incluso muy verdes.
Minería de artículos investigadores

Tshitoyan y su equipo han optado por otro enfoque. Según publican en Nature, han conseguido extraer conocimientos que incluso actualmente estaban dispersos (y ocultos) en millones de artículos investigadoresde forma efectiva debido a un algoritmo de aprendizaje automático.

los investigadores investigan cómo usar la IA para fabricar procesadores de diamante
Para ello, el equipo recopiló 3,3 millones de resúmenes de artículos sobre ciencias de los componentes publicados entre 1922 y 2018. Estos resúmenes se procesaron (para descartar textos que no estuvieran en inglés, etc… incluso dejarlos en un millón y medio) y se analizaron con un algoritmo de aprendizaje automático no supervisado (Word2vec). Ese algoritmo utiliza redes neuronales para realizar estimaciones encima del concepto de las palabras y sus patrones de uso en el texto original.
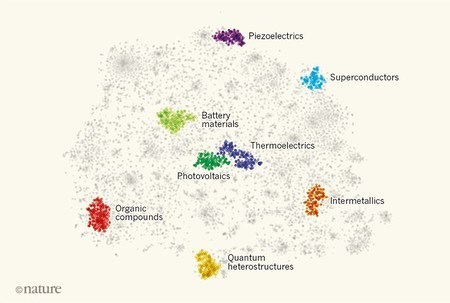
Ahí estaba la clave. Al analizar el banco de textos, los investigadores descubrieron que el algoritmo era capaz de identificar posibles componentes relacionados con diferentes propiedades físicas y eléctricas. Por ejemplo, entrenaron al sistema para predecir la probabilidad de que el nombre de un material en particular coexistiera con el término «termoeléctrico». Fue un éxito, pero hay que identificar que eso era facil.
 Nature
NatureLo interesante vino después, cuando buscaron componentes que, aunque no se habían relacionado directamente con la termoelectricidad, sí tenían una fuerte relación semántica según los examen previos del algoritmo. En este suceso, para evaluar su efectividad, los expertos cogieron un año al azar y pidieron al sistema que seleccionara los componentes con posibles propiedades termoeléctricas con la evidencia disponible. Y, sorprendentemente, además funcionó: los componentes seleccionados tenían ocho veces más probabilidad de haber sido estudiados, con éxito, en los siguientes un lustro.
El equipo investigó diferentes ideas como ‘fotovoltaico’ o ‘ferroeléctrico’ con resultados muy similares. Resultados que velozmente han disparado la imaginación de la gente con sus posibles aplicaciones en los más distintos campos del conocer. Cada año se publican más de dos millones de artículos investigadores, ¿Qué misterios habrá ocultos en esa enorme cantidad de trabajo? Me temo que la contestación a esa duda la poseeremos anteriormente de lo que podríamos esperar.
La entrada Una IA se lee un millón y medio de artículos científicos y encuentra cosas que los científicos no sabían ni que existían se publicó primero en Mundo oculto.